At Papercup, we’ve built over a hundred proprietary (custom-made) AI voices which we use to automate dubbing. Our voices are customizable, they speak different languages and are used to dub content for customers like Bloomberg, World Poker Tour and Jamie Oliver. Here we pull back the curtain to show you how we design the most expressive AI voices on the market.
What are AI voices?
AI voices, also known as synthetic voices, text-to-speech or speech-to-speech systems, are artificial technologies designed to speak any sentence like a human would. These digital voices simulate human speech using deep learning models to recreate human-like tones and emotions. All deep learning voice models are trained using human speech recordings to accurately replicate how we speak.
What are AI voices used for?
Synthetic voices have many different use cases: home assistants, voicing video game characters, generating celebrity voices accessibility for the hard of hearing, or dubbing videos into other languages, as we do here at Papercup. For each use case, the AI voice models must be designed differently. The most cutting-edge, lifelike AI voices on the market are trained specifically on human speech data relating to the use case (as opposed to pre-made voices pulled in via APIs).
How Papercup makes AI voices
At Papercup, we’ve developed AI models designed to dub videos in the media and entertainment and non-media corporate space that require different levels of expressivity. These span reality TV, lifestyle, news and documentaries, kids’ shows and drama, training and marketing videos. Building AI voices that can deliver high quality across a broad genre of content types involves many moving parts and requires deep machine-learning knowledge. Let’s delve into the technology that drives our synthetic speech.
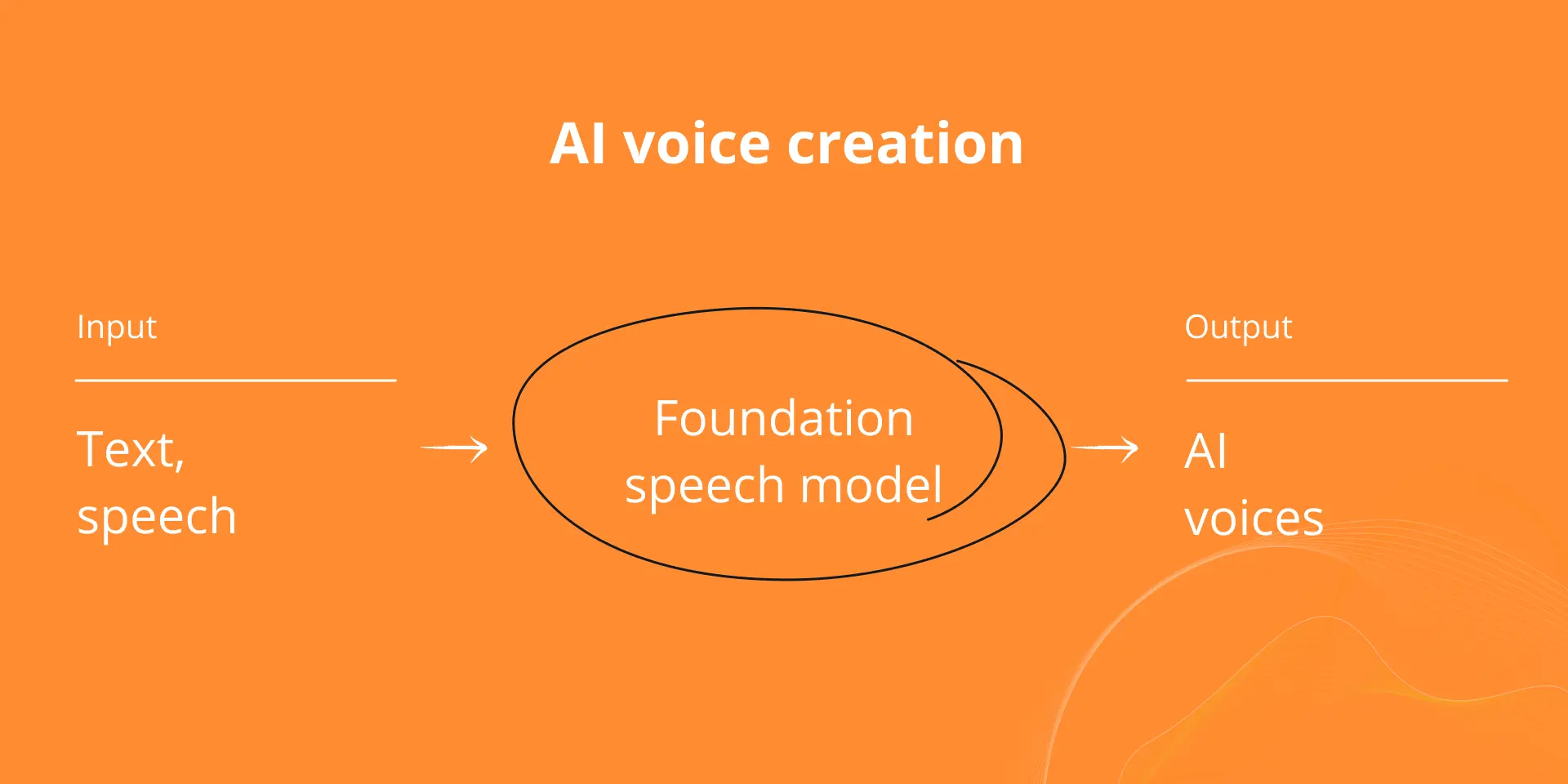
The most common approach using AI voice models is text-to-speech. In text-to-speech, the input is a text version of the content you want to be spoken (e.g. the translated video transcript) and speech is the output. Another common approach using AI voice models is speech-to-speech (also called voice conversion), where the input is human speech, and this is converted to sound like the voice of another person. Finally, there is cross-lingual speech-to-speech (also called speech-to-speech translation) where the input is human speech in one language (e.g. English video) and the output is the translated speech (e.g. Spanish audio). At Papercup, we build AI voices using all of these approaches.
What’s the difference between AI voices and human speech?
The process of human speech creation is incredibly complicated. Speech conveys two main types of information: the spoken words or what is said (linguistic information); and the meaning that is inferred by how the words are delivered (prosodic information) such as humour and sarcasm. Our head of product Kilian Butler wrote about this in this blog.
The principle difference between human speech and generated speech is that the human brain tackles what is said and how it’s delivered in tandem, while in synthetic speech these have historically been treated as distinct tasks. At Papercup, we’re laser-focused on replicating the human ability to deliver linguistic information (the what) and prosodic meaning (the how) simultaneously. We use large multi-modal language models as part of our text-to-speech systems to infer meaning represented by various prosodic attributes (for example: stress, rhythm, and pitch).
How data is used to create AI voices
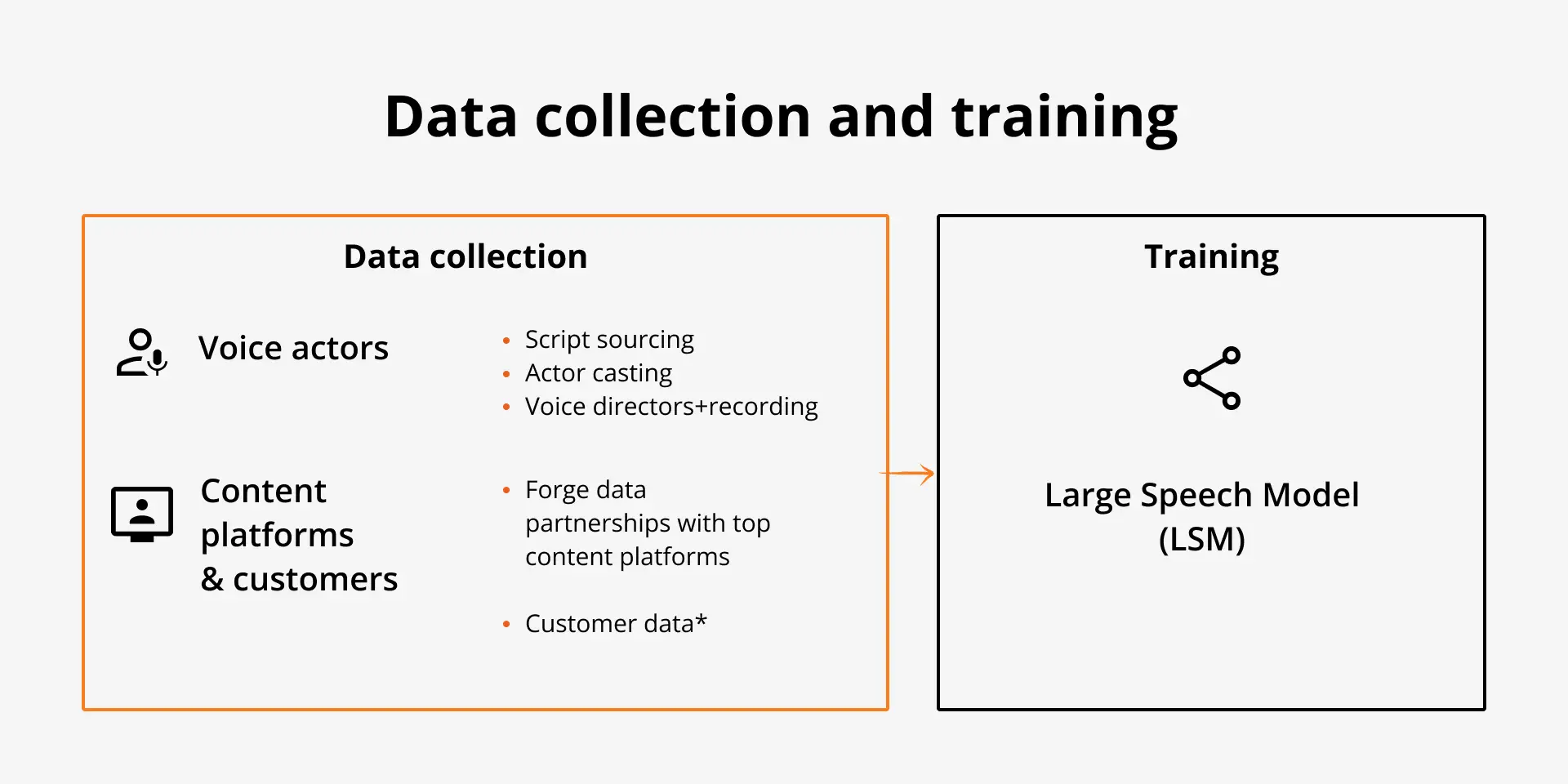
As you’ve likely heard, AI is all about the data and AI voices are no different. If the data used to create an AI voice is low quality, then the AI voice will also be low quality; if the data is boring and unexpressive, the AI voice will be boring too. We need our training data to be high-quality and expressive so that this is reflected in how the AI voice sounds. To meet this high-quality bar, we spend a lot of time collecting the best data to build our AI voice models. Our bank of proprietary voices is all based on recordings from professional voice actors in one of our recording studios. We work with the studios on a regular basis and all voice actors give us explicit permission to use their voice identity for our use cases.
We obsess over all details in the data collection process: we source, curate, and proofread acting scripts; we put out casting calls and pick only the best voices; we work with voice directors to make sure the voice actors are reading the scripts naturally; and our audio engineers at best in class at post-production. Then we do all this for every language we offer.
In addition to this, we work with our data partners and customers to incorporate additional training data into our system. We use this much larger volume of data to power our foundational speech model, this is like ChatGPT but for speech (more on that below). By providing a wide range of data to this foundational speech model our final AI voices are more reliable and expressive.
How are AI voice models trained?
To build an AI voice model, we go through a process called “training,” which involves showing the model many examples of speech. This lets the AI model understand how to generate new speech when we give it a sentence it’s never seen before.
In our case, our AI voice models are built on a foundational speech model we developed in-house. This Large Speech Model (LSM) is much like the Large Language Models (LLMs) used behind the scenes by products like ChatGPT. We give this foundational speech model a huge volume of data: years’ worth of speech data. This massive-scale data allows our foundational speech model to learn all about the patterns of words and expressivity.
But we’re not yet done… many of these foundational speech models produce noisy and low-quality voices so we continue to train this foundational speech model on our proprietary data from the voice actors we work with personally. This has many benefits: it ensures that our AI voice model produces speech with a voice identity belonging to someone who has given us explicit permission to use their voice. It makes our AI voice model much more reliable because the voice actors we record with produce much more expressive speech. Training with this proprietary data also makes our AI voices sound much more expressive and realistic.
How we produce the highest quality voices
When we build new AI voice models we test extensively to ensure they are reliable. We make sure they sound natural and high quality, will correctly pronounce words (including brand terms), and will get the expressivity of speech correct for each sentence and scene in a video.
After our voices are deployed for dubbing, they undergo a rigorous quality assurance process before they hit live channels. Our team of translators checks the translation and dubbed audio and adjusts the accuracy of the translations and the speaker style, tone and pronunciation of the AI voice if necessary.
How do AI voices generate speech for dubbing?
The human-verified translation is the starting point for videos dubbed with our AI voices. This allows us to safely and reliably localize content by limiting the risk of AI voice “hallucinations”: a common behaviour of generative AI (like ChatGPT) where the AI model produces expected, false, misleading, or offensive content.
After giving the translation to the AI voice model, we provide it with the identity we want it to sound like, we can either cast a voice from our bank of proprietary AI voice identities or we can voice clone the identity from the original content (something we only do with the explicit permission from that actor/influencer).
With the translation and the voice identity information, our AI voice model generates the translated speech. Our AI model will choose an appropriate way of expressing the speech, but we also have the option to customize the expressivity by changing the inflection, rhythm, volume, and style. We can even make the AI voice whisper and shout!
Continual improvement unlocks every content type
Our AI researchers collect more data from our recording studios and data partners as they continue their work. This data accumulation is always focused on the most expressive content so that we can continue to unlock new genres of video types. We continually release updates to our AI voices to ensure that they remain the most expressive in the market and are able to meet our customers’ and their audiences’, expectations.
If you’d like to dub your videos with our lifelike AI voices. Get in touch.