https://www.papercup.com/blog/large-language-models Article by Papercup’s Head of Product, Kilian Butler
For hundreds of years, people have been striving to replicate the capabilities of human speech, employing technologies as varied as resonance tubes and machine learning. From HAL 9000 to C-3PO, KITT from ‘Knight Rider’ and Samantha from ‘Her’, fiction is rich with examples of computers that have mastered human speech.
AI and spatial computing are transitioning from science fiction into reality, marking the onset of a new generation of technology. Speech will be a core medium of interaction with AIs as they improve. To many it may feel like speech is mature compared to technologies like LLMs, but this underestimates how much information we convey in a sentence. Speech is a nuanced process of meaning-making that requires true understanding of human communication. In this blog we dive into this challenge: prosody generation!
The last few decades have seen significant improvements in electronic speech synthesis; progress that is audible when comparing the robotic tones of Stephen Hawking’s 1980s speech system, Equalizer, to the realistic speech produced by AI dubbing available on YouTube and streaming platforms today. However despite significant advancement in speech synthesis in recent years, computers still lag significantly behind humans in speech capabilities.
Machine learning techniques have advanced significantly but we must recognise that the creation of human speech is an extraordinarily complex process involving an intricate partnership between mind and body.
Speech enables humans to communicate using sound. It conveys information in two central ways: the words spoken (linguistic information) and how the words are said (prosodic information). How something is said can be as important as what is said. Prosody (how things are said) includes the patterns of stress, rhythm and intonation that determine how an utterance is delivered and communicates additional information to the words that allows us to infer meaning and intentions. Commonly referred to as expressivity, the prosody of a sentence can convey the speakers’ emotions, certainty, or any number of aspects related to their physical or mental state. Are they sincere or insincere? Was their speech planned or off-the-cuff? Prosody planning, the process by which we determine how to speak, is still relatively understudied and crucially cannot be separated from language production itself.
C-3PO, the metallic humanoid robot from the Star Wars series, represents the platonic ideal of a synthetic speaker.
He communicates his feelings clearly by producing the tones and intonations that leave no doubt of his worries and complaints, all delivered in Received Pronunciation British accent. He’s a perfect example of an advanced synthesis system that generates prosodically appropriate speech. To advance towards this vision, what must the next generation of speech synthesis models be capable of?
The prosody problem
The primary role of prosodic features in speech is to enhance communication between the speaker and the listener. Different subtexts in conversation can be communicated through prosodic information like:
- Disagreeing with someone
- Trying to subtly change the topic
- Stopping someone interrupting you
- Thinking while speaking slower
- Showing you don’t care
- Looking for an emotional response, e.g. empathy
The pitch, duration, inflections, intensity, loudness, and a whole host of other elements all represent meaning, or contribute to a function in spoken communications. This function refers to the illocutionary force of an utterance, which is defined as ‘the speaker’s intention in producing that utterance’. For example, if you didn’t want to to go an event, but your friend wants you to join them you might say “Yeah, maybe we should” but with a pause on “yeah” to display you’re uncertain. The illocutionary force here is you communicating that you don’t want to go (despite the words saying otherwise). The very common speech synthesis use case of audible directions (i.e. Garmin, Google Maps) are notable by their lack of illocutionary force. Research teams for these products will be looking to improve on the passive intonation, where all directions are treated equally.
Speech is an incredibly complex problem with multiple axes of variation. Minor changes in prosody can indicate significant changes in meaning, much in the same way that changes to the tone, style or grammar can convey subtext in language (try asking ChatGPT to make your next email passive aggressive).
Speech includes an array of other elements that are key in communications, but challenging to model: sarcasm, attitude (towards yourself or someone else), interruptions, laughter, filler phrases (ums and ahs etc.) and other non-verbal utterances. Speech is further enriched in its role as a communicative function by the presence of disfluencies and non-verbal speech.
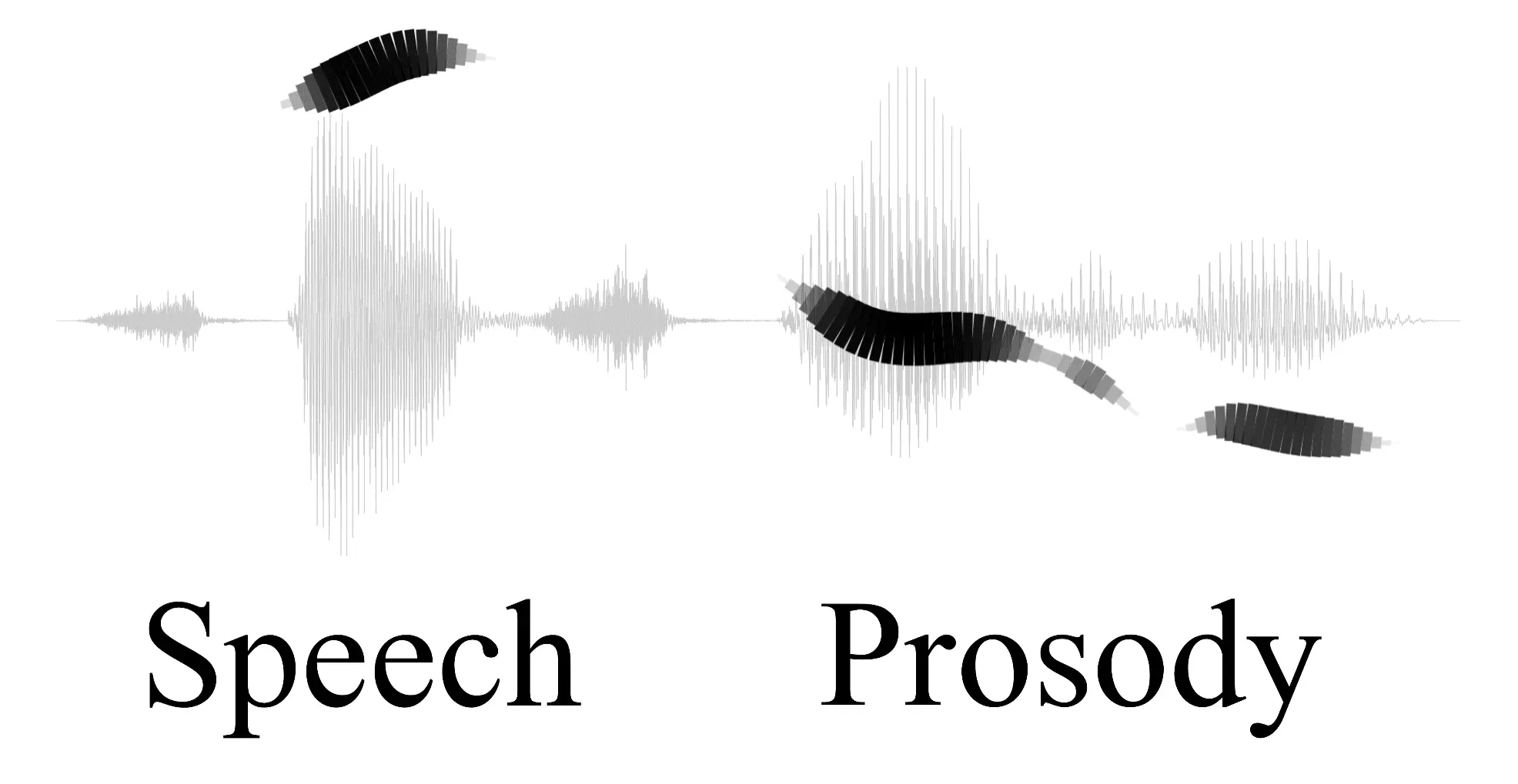
A visual representation of speech & prosody. The grey waveform indicating the sound of the words ‘Speech’ & ‘Prosody’, with the black brushstrokes displaying the prosodic elements of pitch and periodicity. (Source: www.nigelward.com/prosody)
Current speech synthesis systems struggle to convey the depth of information that a human is capable of. The fantastic performance of voice cloning models can oftentimes obscure the relative paucity of prosodic features. Models with prosody generation and cross-lingual prosody transfer capabilities (speech-to-speech translation) are however excitingly starting to show promise, but there are unique aspects about the medium that will need to be addressed.
Synthetic speech products must generate both words and prosody from a given context. Large Language Models (LLMs) have displayed impressive improvements in computers’ ability to generate contextual language in the form of text. However, this addresses only half of what it takes to build communicative, intelligent systems. With LLMs, the task is to generate words; in speech models the task is to generate prosody (since synthetic speech can now generate high acoustic quality and accurate pronunciation). Future modelling improvements will necessitate appropriate prosody generation in a less sequential manner. Current state of the art multi-modal LLMs generate linguistic information and feed it to text-to-speech systems to infer prosody. In humans, however, the prosody and linguistic planning processes are more closely intertwined.
Even experts in the field of prosody still do not have a complete understanding of the structure and rules that we follow when communicating. English prosody is comparatively well understood, but there is still substantial debate among academics about how it really works. Understanding of non-English prosody is very limited and sparse, much less the cross-lingual mappings of prosody across languages, dialects and cultures.
The prosody problem exists among a set of problems that were previously out of reach for traditional software. These are challenges that relate to things like natural language, images, and physical space. One could refer to this type of thing as an ‘AI hard’ problem – a problem that can now conceivably be unlocked with modern machine learning techniques and hardware. Our limited understanding of prosody means that we cannot write an exhaustive set of rules which would govern how prosody changes meaning in context. In the same way that LLMs work better than rules based algorithms for contextual language, speech models must learn from data the ability to generate appropriate results from a given context. But what are the other unique aspects of speech that will pose challenges for product teams and researchers?
Other challenges in speech
Speech is a continuous signal processing challenge. This contrasts with image or language generation, which is considerably easier to represent. In this way, speech generation models are more analogous to generative video modelling, which is considerably less mature than image or language generation. This means speech is harder to tokenise and all tokens must be converted into analog signals. This last mile is not present in text or image generation.
Spoken languages are also extremely fragmented. Roughly two thirds of the world speak the top five languages. The remaining third of the world speaks a long tail of thousands of languages. The relative performance of LLMs across different languages (especially low-resource languages) is indicative of the challenges that speech generation will face.
The commercial attempts at productizing personal assistants can give a sense of the scale of the challenge. Apple’s Siri was launched in 2011 and Amazon’s Alexa has been funded to the tune of tens of billions of dollars. Both systems are still largely limited in their ability to generate prosodically appropriate speech despite extensive research and development. Both have made efforts to add some realistic prosodic feature generation, but when these features are applied to the wrong context it can be jarring, invoking the uncanny valley.
Despite the long history of vocoders and text-to-speech, speech is a much less mature field from an machine learning perspective with a comparatively smaller field of talent working on the challenges. Text-to-speech systems have been able to produce speech, which communicates lexical information (the words themselves) and was intelligible for several decades. In essence, text-to-speech was ‘good enough’ for a limited set of use cases for a long time. This influenced the shape of the research industry itself. Less machine learning talent flowed to speech (in favour of areas like computer vision or natural language processing), resulting in optimizations being applied at a component level (like vocoders) rather than in an end-to-end singular system.
Exciting progress has been made in recent years and there is significant potential upside in solving for prosody generation. As a result speech is already attracting more and more talent within machine learning, compounding the benefit to end users.
So what’s next?
Many modelling, data, architectural and operational techniques have yet to be applied in full to speech synthesis. However, we are beginning to see green shoots here and there is undoubtably great strides to be made in porting the learnings from other fields.
Machine learning teams will learn from and collaborate with anthropologists, linguists and other experts in the field of speech and language to deploy prosodic models globally. Communication is not a one size fits all system, with high and low context cultures deploying differing methods. Germanic cultures, for instance, communicate directly with language, whereas Asian or Latin cultures are more nuanced in their communication. Interestingly, it appears that human speech encodes information at roughly the same rate, regardless of language.
The broad application of speech encoding and decoding holds immense commercial promise. By enabling computers to generate and interpret prosodic nuances, we can surmount language barriers and facilitate smoother global communication. Advanced machine learning models, particularly those with multi-modal capabilities, are poised to become integral to human-computer interaction. In this dynamic landscape, AI laboratories, startups, and the open-source community are expected to integrate speech input and synthesis more deeply into their multi-modal systems. This integration will not only enhance the adoption of Large Language Models (LLMs) across businesses and consumer sectors but also enrich user engagement. Speech synthesis that is both expressive and captivating will be key in attracting and retaining users. Moreover, systems capable of perceptual decoding stand to respond more intuitively to user prompts and intentions, significantly elevating the user experience.
AI dubbing is a market ripe to power the acceleration of speech synthesis research. It is a prime example of deflationary AI software, which can provide accessibility for information and entertainment globally at cost and scale previously impossible. Human-in-the-loop (the process in which humans check and adjust the generated audio) can control for failure modes in prosody prediction and provide crucial data to improve model performance over time.
Conclusion
It’s evident that while significant progress has been made in speech synthesis, the prosody problem will be the defining challenge of the next generation of models. The opportunity is vast – the ability to revolutionize how we interact with technology, enhancing global communication and accessibility. We must also be mindful of the ethical dimensions of this technology, ensuring it enriches rather than exploits our human interactions.
The journey towards creating lifelike synthetic speech is not just about technological achievement; it’s about deepening our understanding of human communication and its potential in bridging divides
We might still be a long way from creating intelligent C-3PO level communicators, but the momentum in the field is building. Expect exciting things from Papercup and the industry as a whole.
Huge thanks to my colleagues at Papercup for their assistance in pulling this together. I’m very lucky to work alongside some of the world’s foremost experts in prosody and synthetic speech. Special thanks to Hannah, Zack, Simon, Devang, Doniyor, James, Prass, and Jesse for answering my many questions, editing and reading drafts. Additional thanks to Nigel Ward for his time and thoughts on prosody. And thank you to anyone who took the time to read this and found it interesting.