From chatbots and automatic dubbing to voice cloning and conversion, speech technology is making waves across the media and creative industries. But for those who aren’t engineers, its technical terms can get in the way of really getting to grips with the technology.
For creators and content owners looking to integrate AI into their way of working, this creates a needless barrier, which could mean they miss out on using AI dubbing to reach global audiences via YouTube’s MLA tracks or knowing the right questions to ask when trying to find the best voice generation tool or AI dubbing platform.
To help lend some clarity, we’ve compiled a speech technology glossary covering the subsets of AI involved in speech creation, the fundamentals of AI models, and some essential speech-specific terms.
Types of AI used in speech technology:
Generative AI
As the name suggests, Generative AI is a specific type of artificial intelligence that can be used to create new data, rather than just make decisions and predictions. It uses AI models to learn patterns from large datasets, then takes things one step further by creating new content that’s hard to distinguish from human-generated output. Users can input prompts and get output in a variety of formats, from images and text to audio.
Advances in Generative AI are happening quickly, and it already has diverse applications from ChatGPT and DALL-E to synthetic speech and AI dubbing.
Natural language processing
Natural Language Processing (NLP) merges linguistics and computer science to enable computers to interpret and automatically transcribe speech into coherent text. It works by reading text and applying various techniques such as deep learning models to analyse it. It works by taking natural language data (spoken or text-based data created by humans) and applying various techniques such as deep learning models to analyse it.”
The combination of these technologies allows the computer to work with the meaning of the language, rather than just the words produced. This makes it possible for AI to power advanced use cases such as analyzing speech sentiment, translating input from one language to another, and converting speech into text.
AI and Machine Learning fundamentals:
Model
An AI model is a mathematical program (sometimes called an ‘algorithm’) that can mimic human intelligence by making predictions or decisions. Models are fed large amounts of training data, and ‘learn’ from this information how to make accurate predictions for new, unseen data. They are the core components of machine learning and deep learning technologies.
A machine learning model learns from its previous decisions and iterates its approach over time. This leads to highly sophisticated models such as the ones used in natural language processing, speech recognition, and speech synthesis.
Large language model
A large language model is a specific type of AI model that can process natural language. Using deep learning techniques, it is trained on vast amounts of text speech data to grasp language patterns. Since large language models require a lot of computational power, they’re usually run by tech companies with large resources, and accessed via an Application Programming Interface (API) or a website (like in the case of ChatGPT). See the API definition below!
Large language models are used to generate text that sounds like it comes from a human. As well as being the technology behind ChatGPT, they’re also used for automatic speech recognition and to translate text from one language to another.
Training data
Training data is how AI models are taught how to act. Datasets with labeled input samples (such as text, images, or audio) are fed into an AI model. From this data, the model learns to recognize patterns and make predictions or decisions for new, unseen data. For example, for a speech recognition use case, speech files with matching transcriptions might be used to teach a model to recognize phrases and patterns.
API
API stands for Application Programming Interface. These are sets of rules that allow different software applications to communicate with each other. APIs enable developers to access functionalities or data from other services or platforms. For example developers can use APIs to access a large language model such as ChatGPT to power their own products.
Human-in-the-loop
Human-in-the-loop refers to an approach in AI and machine learning systems where human involvement is incorporated in the decision-making process. Humans provide feedback, validation, or oversight to the AI model, ensuring better accuracy in the system’s outputs. At Papercup, we use expert human translators alongside our AI dubbing solution to assess and correct intonation, add language-specific context, and assure translation quality.
AI speech technology definitions:
Text-to-speech
Text-to-speech (TTS) technology converts written text into spoken audio output. Text-to-speech systems use deep learning models to interpret and generate human-like speech, enabling applications like voice interfaces, audiobook narration, and accessibility tools for the visually impaired. This technology can be provided stand-alone, where users have to input text to receive generated speech output, or incorporated into an end-to-end dubbing solution like Papercup.
Speech recognition
Speech recognition, also known as Automatic Speech Recognition (ASR), is essentially the opposite of text-to-speech. Instead of taking text and turning it into speech, it takes human speech, processes it, and turns it into text (or a machine-readable format). Speech recognition systems are complex technologies that are often based on deep learning models. They enable voice-to-text applications such as Siri and Alexa and are an important part of the AI dubbing workflow, since they enable creators to input speech and create an automatic transcription.
Synthetic speech
Synthetic speech is the artificially produced output of text-to-speech (TTS) or voice synthesis technology. It mimics natural-sounding human speech, and has a variety of use cases, from allowing computers and devices to communicate audibly with users to voice generation for media, film, and AI dubbing. Not all synthetic speech is created equal: when assessing speech technology, users should evaluate expressivity, vocal quality, and vocal fidelity (if localizing for a new language).
Expressivity
In the context of speech technology, expressivity refers to the ability of an AI model to convey emotions, nuances, and variations in tone. Highly expressive AI models like Papercup’s can generate text or speech that reflects different moods, personalities, and communication styles. This requires significant ongoing work from machine learning teams, so be wary of providers offering a large range of off-the-shelf options. Typically, these will be pulled in from other providers like Google, with little (if any) customization done on top.
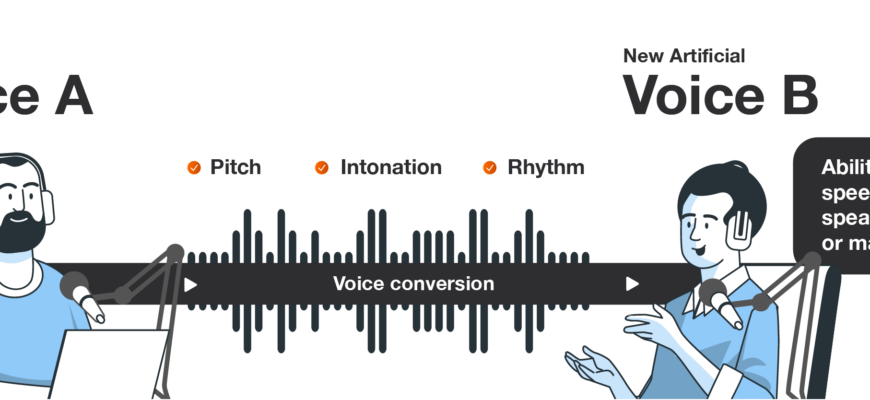
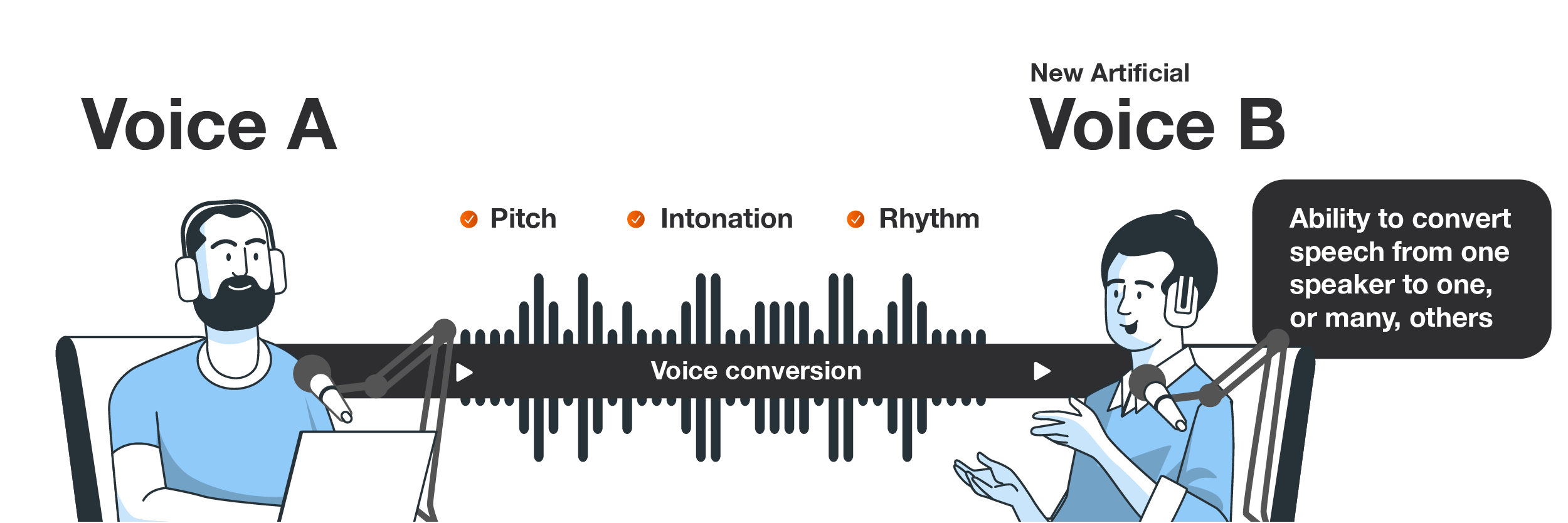
Voice conversion
Voice conversion is the process of modifying a person’s speech to make it sound like another person’s voice without changing what has been said. This technology uses machine learning and signal processing techniques to achieve a convincing and natural-sounding transformation. The vocal output retains characteristics of the target speaker without creating the ethical and legal implications present in voice cloning.
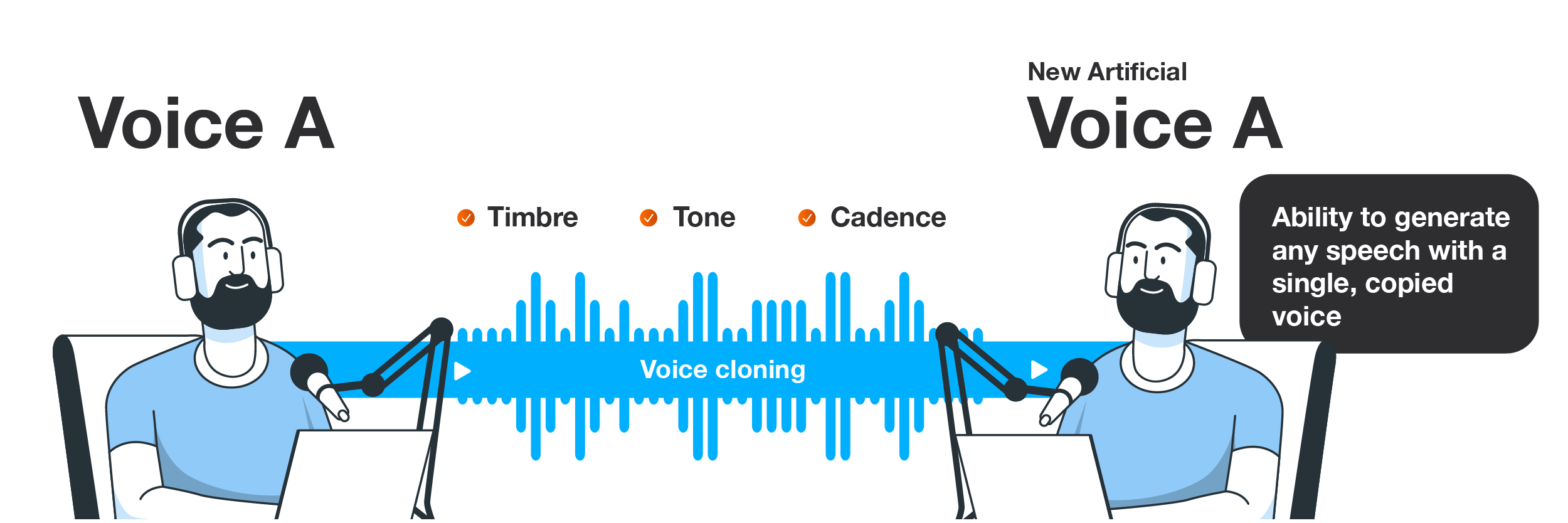
Voice cloning
Voice cloning uses machine learning and speech synthesis techniques to create an artificial voice that sounds just like a specific individual. It does this by mimicking the speech patterns, tone, and timbre of the person. While cloned voices have been used in Hollywood productions like the Star Wars franchise, they’re not without controversy – as the documentary that deep faked Antony Bourdain’s voice after his death shows. Companies that use this technology need to think carefully about how to maintain ongoing consent, and make it clear they’re using AI to retain audience trust.
==
From automatic speech recognition to text-to-speech technology, generative speech can unlock text-based content, translate speech to target languages, and maintain vocal fidelity. And with human-in-the-loop quality assurance and vocal expressivity, there’s no reason AI voices can’t sound just as good as the original.
Whether you’re at the start of your AI dubbing journey and want to learn more about the process, or are looking for a more efficient way to localize video at scale, Papercup’s AI dubbing experts can help. Get in touch to learn more.