Breaking new ground: AI voices and AI dubbing for kid’s content
Creating voices for kids’ content using artificial intelligence is uniquely challenging. This expansive genre contains a huge range of voices, from exaggerated, highly expressive adult voices (think Blippi) to genuine children’s ones. The expressive range across these various voices is vast and complex: the unique high-energy excitement of a cartoon character, for instance, requires different training data to, say, the subtle emotional nuances – unique timbre and pitch – of a child’s natural voice.
Here at Papercup, we’ve been working on using our machine learning technology to recreate children’s voices so that kids’ content owners can amplify their content globally. And recently, we’ve had our most significant breakthrough yet – our most realistic kids’ voices to date, indistinguishable from the real thing. Have a listen and find out a bit about the journey we’ve been on.
Why, exactly, is it hard to create kids’ voices?
The challenges of creating kids’ voices are magnified in the realm of Text-to-Speech (TTS) technology. Not only must the TTS system replicate the unique sound of a child’s voice, but it must also manage to convey the extensive range of expressivity required. This requires high-quality training data that represents this expansive genre of content.
Overcoming the challenges of creating kids’ voices?
Our technology uses advanced machine learning models and deep neural networks, which can understand and reproduce the intricate details of human speech. These models are trained on extensive datasets to ensure they can generate accurate, expressive, and engaging voices.
However, applying this stack to develop children’s voices was uncharted territory; we were unsure how well our models would handle such a distinct type of speech and expressivity.
As always, we began by commissioning voice data from child and adolescent voice actors, which we then used to train our models. With the launch of Cross-lingual Prosody Transfer (XLPT), our technology stack has proven incredibly versatile and robust, accommodating various speech profiles and expressive needs. The technology adapted seamlessly, producing high-quality synthetic voices that accurately replicate the nuances of children’s speech.
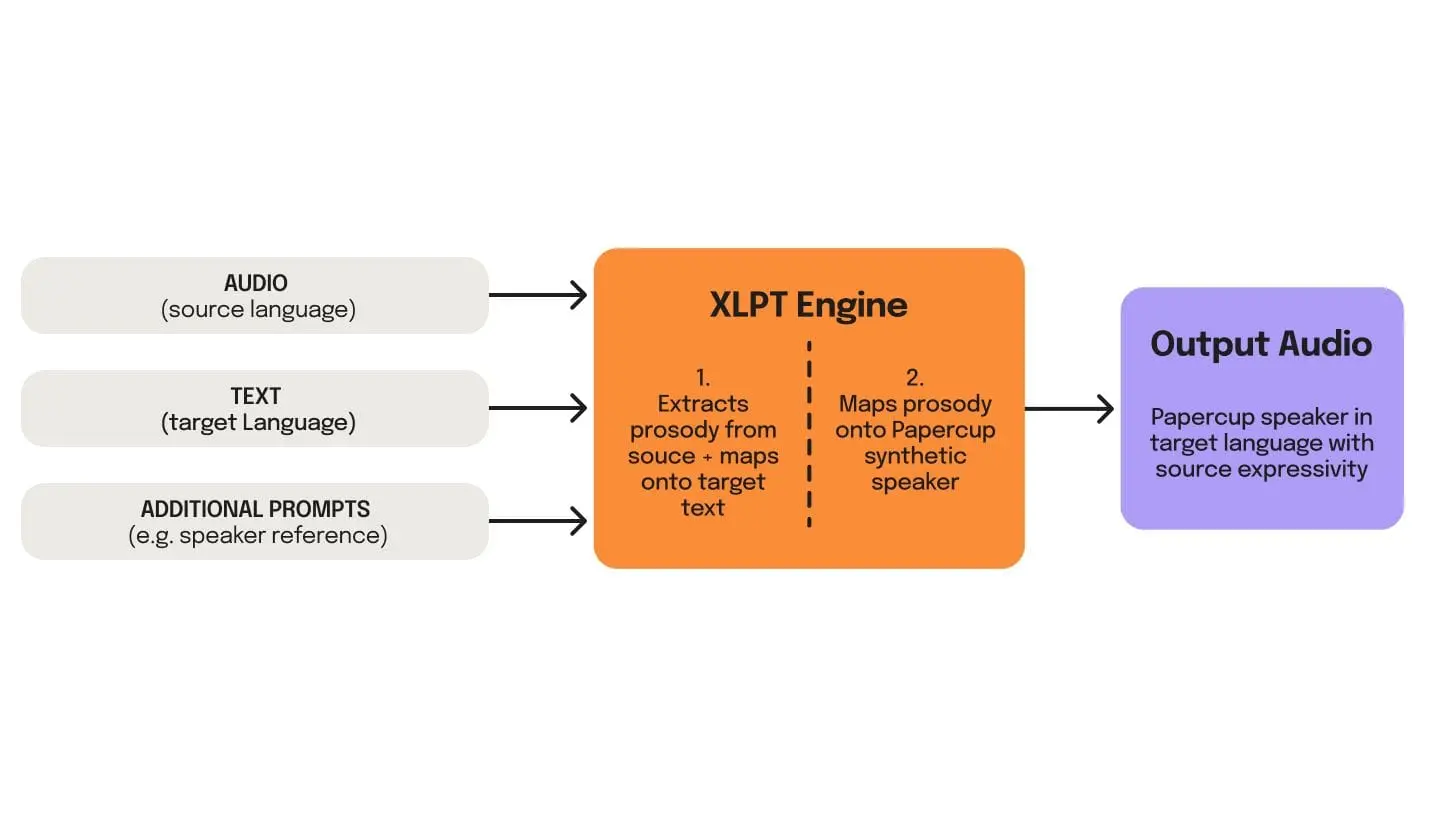
This breakthrough is not just about technological achievement; it has profound implications for the industry. It opens up new possibilities for creating engaging, high-quality kids’ content at scale. From animated series to educational tools, the ability to generate authentic and expressive children’s voices can enhance the storytelling and learning experience for young audiences globally.
Learn more here.