- Speech AI has 10x’d: purpose, evaluation, and products
- Speech as communication
- Speech products in practice
- AI dubbing (e.g. Papercup)
- Mapping navigation (e.g. Google Maps, Apple Maps)
- Digital avatar videos (e.g. HeyGen, Synthesia)
- Evaluation as a key enabler
- Preference without purpose
- Moving beyond classical evaluations
- Next up for speech evaluation
- Conclusion
Speech AI has 10x’d: purpose, evaluation, and products
This post is for anyone building AI models, rethinking human-computer interaction, or just wanting to build really great products. It explores the implications of advanced speech capabilities in machine learning, drawing on my five-plus years of experience and conversations building AI-native products.
AI speech has a significant capability overhang—its model capabilities far outpace their current user and economic impact. We now have the potential to generate expressive speech that can unlock transformative user experiences. From model development to product design, R&D teams must now confront the implications of computers that can truly communicate verbally.
Speech is one of our most fundamental forms of communication, yet it’s often treated as just another feature in modern products. While voice interfaces are widely recognized as key to the future, we continue to evaluate AI speech with outdated frameworks, akin to 1990s text-to-speech. This disconnect between speech’s potential and how we build and measure it is holding back the next wave of human-computer interaction.
OpenAI’s GPT-4o Advanced Voice Mode was the first widely available model to showcase multimodal speech capabilities, proving that The Bitter Lesson applies to speech: progress stems from scaling and generalization. But intelligence is no longer the moat—it’s a commodity. The real edge lies in how products leverage these capabilities, redefining speech as a dynamic communication medium.
Speech isn’t just about words—it’s about how they’re said. Prosody transforms meaning, intent, and emotion. This image captures its impact better than any explanation I’ve come across:

We’ll focus on the fundamental purpose of speech: enabling and enriching communication. From theory to practice, we’ll explore how modern speech synthesis solves real-world problems and creates value for businesses and users.
Speech as communication
To build great speech products, we need to understand the ‘job to be done’ of speech: communication. This starts with understanding the anatomy of speech events.
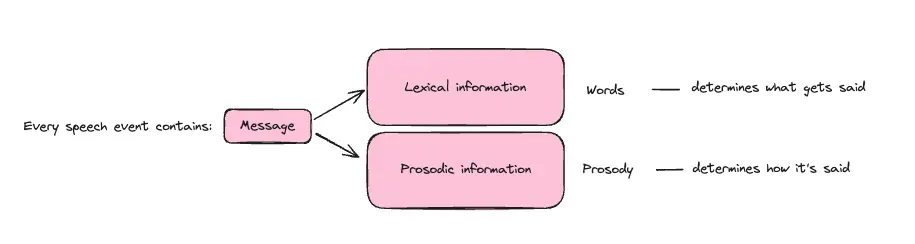
Every instance of spoken communication is a speech event—a single utterance or sentence conveying meaning. Each speech event contains two key components: lexical information (the words, or what is said) and prosodic information (the rhythm, pitch, and tone, or in other words how it’s said). Together, these elements create the message and effectively convey meaning.
A single message without context is generally insufficient to communicate all the information. Who is the intended receiver? What is the speaker responding to? Through what medium is the speech delivered? Linguistics and information theory provide frameworks to help us navigate these complexities when deploying intelligent speech systems.
Roman Jakobson’s model of speech events outlines six interdependent components—sender, receiver, context, message, contact (channel), and code—that together create meaning. A breakdown in any component can disrupt communication. For instance, if the code (shared language or conventions) doesn’t align with the context (situation or cultural backdrop), the receiver may misinterpret the prosody or intent within the message.
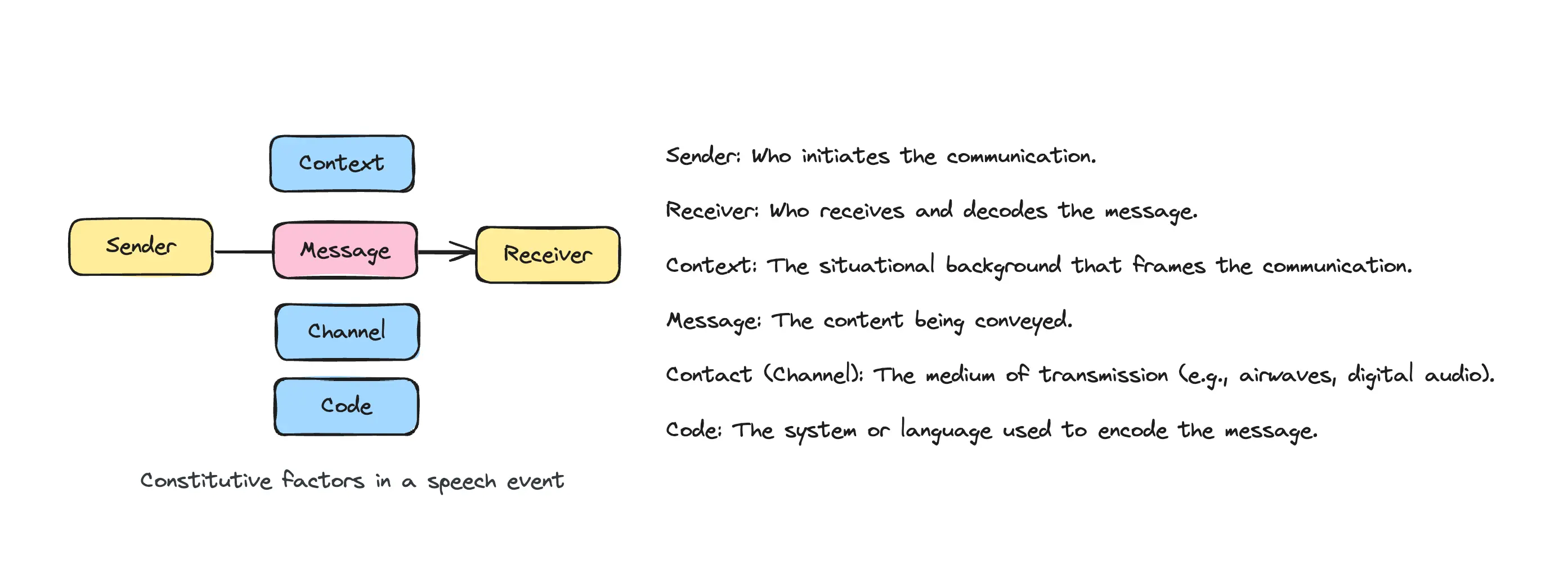
This interplay of factors is crucial for AI speech systems. Success doesn’t come from generating natural-sounding audio—it’s about harmonizing these components to ensure speech achieves its communicative purpose, whether guiding a driver or conveying emotion in a localized dramatic video.
A great starting point for practical exploration is mapping the components of a speech event to the product interaction your user will experience. Use the diagram below to guide this process. Keep in mind, each speech event typically conveys a single message, but user interactions often build into either a conversational exchange (back-and-forth utterances) or a sequence of utterances (such as delivering a set of instructions).
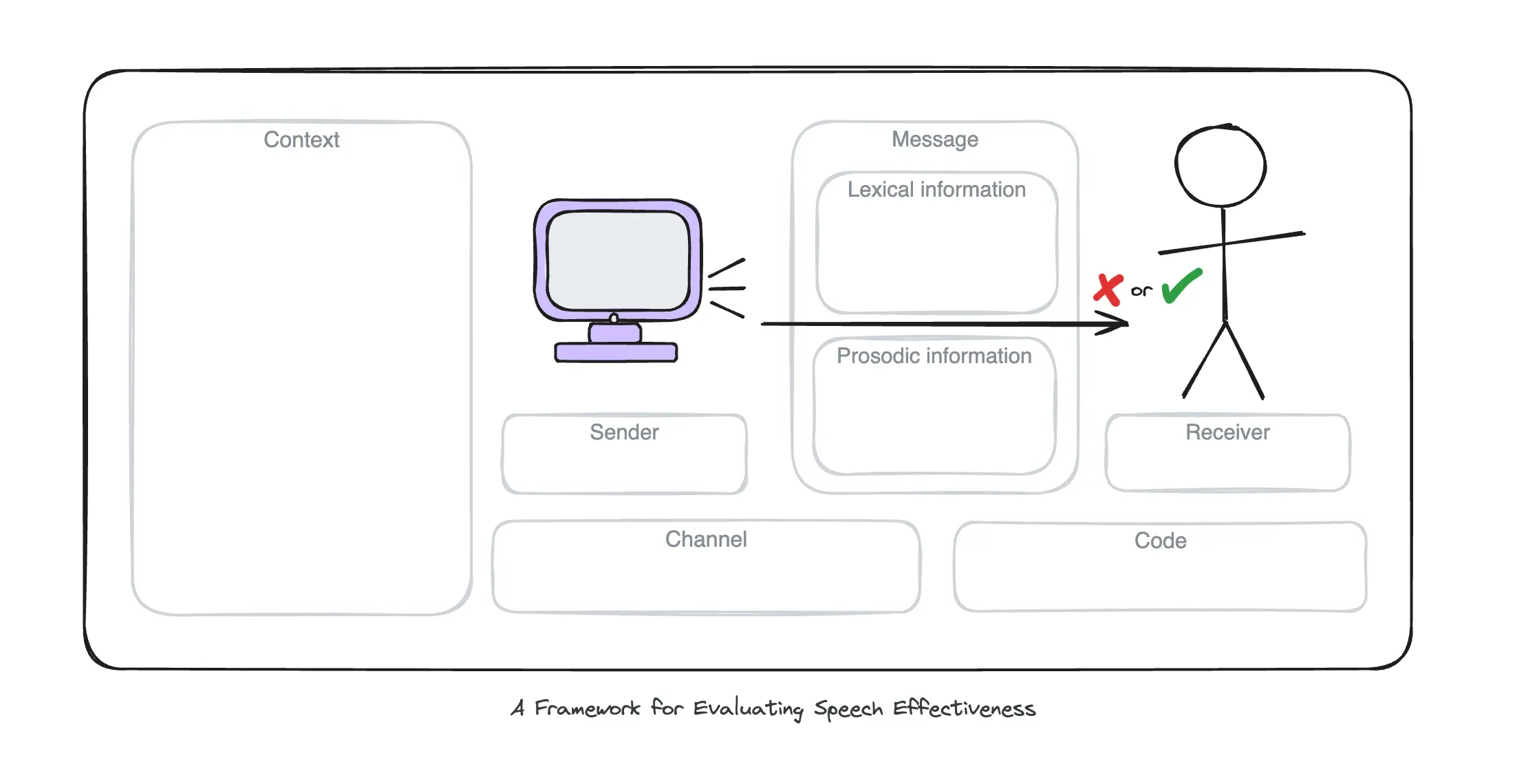
Jakobson’s model offers a solid foundation but it doesn’t fully address how we assess the success of a speech event in practice. The diagram above hints at a positive or negative evaluation, but communication is rarely binary—the receiver may grasp parts of the message or interpret unintended meanings.
For example, a speaker might aim to communicate sincerity or reassurance but unintentionally convey doubt or indifference through their prosody. This challenge is equally relevant for synthetic speech. AI-generated speech must carefully balance prosodic and linguistic elements to avoid undermining the intended communicative goals, ensuring that it conveys both the desired message and tone effectively.
To better understand these challenges, Speech Act Theory adds nuance by highlighting three layers of communication:
• Locutionary Force: The literal meaning of the words
• Illocutionary Force: The intent behind the message
• Perlocutionary Force: The effect on the listener
Synthesized speech must succeed on all three levels. It’s not enough to “sound human”—systems must express intent and achieve the desired impact, whether resolving a frustrated customer’s issue with empathy and precision or making a user feel understood during a virtual conversation.
Speech products in practice
Let’s apply these observations to three product categories where speech is making a significant impact, each with unique challenges, opportunities, and economic implications.
AI dubbing (e.g. Papercup)
AI dubbing is one of the most demanding speech synthesis applications because it must replicate, not originate, expressivity. This requires transferring lexical and prosodic information across languages while preserving the illocutionary force (intent) of the original speech.
Traditionally, prosody transfer reproduced the rhythm, pitch, and tone of source speech directly, often failing to meet cultural expectations. The shift toward prosody translation adapts delivery to the target language and audience. For example, a passionate monologue in English may need a more restrained tone in German to convey authentically. This evolution ensures localized content feels natural, emotionally resonant, and culturally aligned.
Mapping navigation (e.g. Google Maps, Apple Maps)
Navigation systems rely on flat, monotonous delivery, leaving users to infer urgency or intent from words alone. This increases cognitive load and leads to frustration (speaking from experience!).
Dynamic expressivity offers a solution by adapting tone to context. For instance, a firmer tone for “Turn left in 200 meters” can signal urgency, while a calmer tone for “Turn left in 5 kilometers” allows for deliberate planning. By aligning speech with context, navigation systems can improve clarity, reduce cognitive effort, and enhance trust.
Digital avatar videos (e.g. HeyGen, Synthesia)
Digital avatars are revolutionizing video production by reducing costs and enabling rapid localization. These systems can generate videos in multiple languages from a single creation, but localization requires adjustments to the code to reflect linguistic and cultural conventions across regions.
In digital video, alignment between avatars and synthetic speech is crucial. Flat, robotic voices paired with hyper-realistic visuals—or expressive voices with stiff animations—diminish user experience. A safety training video calls for calm authority, while sales enablement content thrives on dynamic, engaging delivery. Cohesion across all elements is vital.
These examples hint at how we should think about enabling speech synthesis as a transformative layer in AI-native products. Realizing its full potential requires evaluation methods that move beyond naturalness to measure how effectively systems communicate and deliver value.
Evaluation as a key enabler
We need to move beyond the simpler world of TTS (text-to-speech), which no longer reflects the reality of intelligent, multimodal systems. These models now integrate diverse inputs and outputs, including text, images, and audio. Advancements in text-to-image generation demonstrate the growing versatility of multimodal research. Modern speech synthesis leverages this progress to produce expressive, contextually rich speech. Clinging to the TTS label underestimates these systems’ potential and narrows our vision for their future applications.
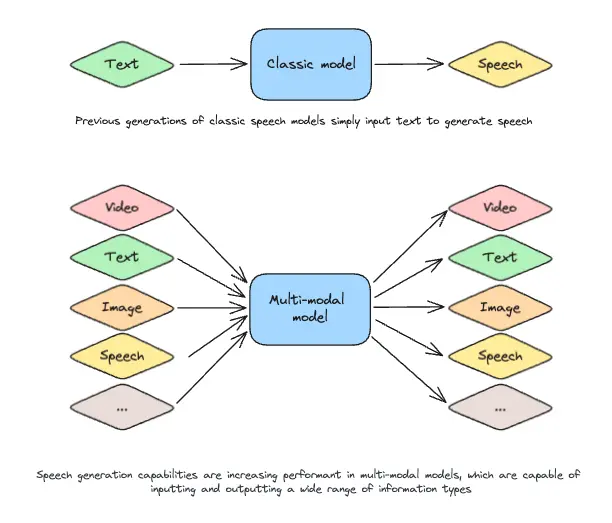
Beyond multimodality, advances in prosody are the hallmark of frontier speech models. However, defining and evaluating prosody in speech synthesis remains a significant challenge, particularly as the field shifts toward nuanced approaches like prosody translation. Recent research has started addressing this gap by exploring methods to evaluate prosodic intent—an area where real-world applications outpace academic progress. At Papercup, we’ve been thinking about this to meet the demands of AI dubbing.
Preference without purpose
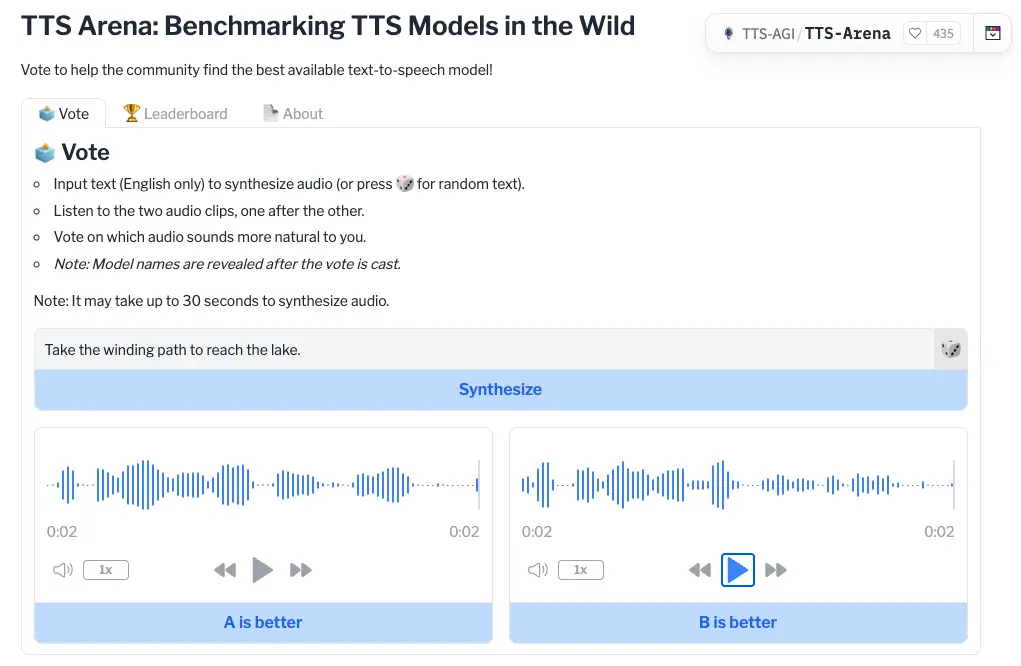
TTS Arena, is a Hugging Face space for ranking speech models, which exemplifies how traditional approaches limit progress. Users compare two sentences and select their preference, but this evaluation is divorced from the speech’s purpose. It provides little insight into what was communicated or how well the speech fulfilled its intended function. Such methods fail to drive meaningful advancements in end-to-end speech synthesis without accounting for communicative context. To unlock the potential of modern systems, we need evaluations that measure how effectively they convey meaning, intent, and emotion in real-world scenarios.
Moving beyond classical evaluations
To design effective evaluation frameworks, we must move beyond intelligibility and naturalness, focusing instead on communicative success. The question isn’t just “Does it sound human?” but “Does it fulfill its purpose?”—whether that’s informing, reassuring, persuading, or entertaining.
Speech Act Theory provides a valuable lens for this shift. By examining the content (locutionary), intent (illocutionary), and impact (perlocutionary) of speech, we can create evaluations that truly reflect real-world communicative goals. Key questions include:
• Is the intended meaning conveyed clearly?
• Does the speech align with the context and intent?
• Does it achieve the desired effect on the listener?
A tutor bot might be evaluated on how effectively its tone and delivery enhance understanding and retention of key concepts, while voice-enabled interactive games could be evaluated on their ability to adapt tone and pacing to sustain user engagement. The combination of engagement-driven chatbots and expressive voices is bound to pose significant societal challenges.
As we advance evaluation frameworks, it’s essential to retain the human element. Speech, one of our oldest and most intuitive forms of communication, predates writing and is deeply rooted in human culture. Automation will be vital for scaling evaluations, but human oversight is critical to ensure these systems align with our values and communicate in meaningful, impactful ways. By blending human judgment with automated tools, we can create systems that prioritize real-world utility over mere model optimization.
Next up for speech evaluation
Modern speech synthesis systems seamlessly integrate text, audio, and other inputs, but evaluations often lag behind this multimodal complexity. Video, as a medium, provides a clearer lens for testing speech performance, particularly in capturing emotional nuance and aligning audio with visual context.
Scalability is another critical challenge. Data-labeling platforms excel in text and image evaluations but lack robust tools for assessing speech. Expanding to evaluate prosody, intent, and emotion requires addressing audio’s unique challenges, from its nuanced nature to cultural variability.
Closing these gaps will enable evaluation frameworks that go beyond naturalness to assess how effectively speech communicates meaning and intent in real-world scenarios.
Conclusion
AI-generated speech systems have reached a pivotal moment. Modern speech systems are highly capable, but their real value lies in enhancing communication—not just technical achievements. Speech systems must deliver meaning, intent, and emotion in natural, intuitive, and impactful ways.
To achieve this, evaluation must move beyond classical paradigms like TTS, embracing frameworks that reflect speech’s role as a communication medium. By designing systems that align with real-world contexts, we can build products that don’t just sound human but truly connect with users.
The evolution of speech in AI must do justice to its position as our most fundamental communication tool. The key to advancing speech technologies lies in critically reflecting on their purpose—to enhance communication.
“I didn’t have time to write a short letter, so I wrote a long one instead.”
Thoughts or feedback? Reach me at [email protected].