Here’s how our machine learning operations team on handling large-scale data
We’re entering a world where many foundational machine learning models are trained on vast amounts of data . To understand how much data, take Llama3, which was trained on 15 trillion data tokens, equivalent to 54.5 billion A4 pages. This is the amount of data required to give models emergent capabilities. Large language models (LLMs) are trained to predict only the next word, but in that process, they learn humour, chemistry, math and nuances of cultures. If we treat an LLM as a black box, the input is some text (your question to ChatGPT), and the output is some other text (ChatGPT’s answer).
Transferring that concept to the field of TTS (text-to-speech) systems, we have an optional additional input and an additional output, which are the source audio and the output audio, respectively. For example, the source audio could refer to audio in an original language in the context of dubbing. Just as in the LLM world, in the audio world, TTS models are getting bigger so that they can tackle more nuanced tasks (whether that’s dubbing, sound effects or music generation) and capture more nuance (emotions, hesitations, prosody) in the source audio, that is the content our customer wants to dub into another language using AI dubbing.
A new generation of text-to-speech models
The previous generation of models had multiple components: some that were aided by machine learning and some which were rule-based.
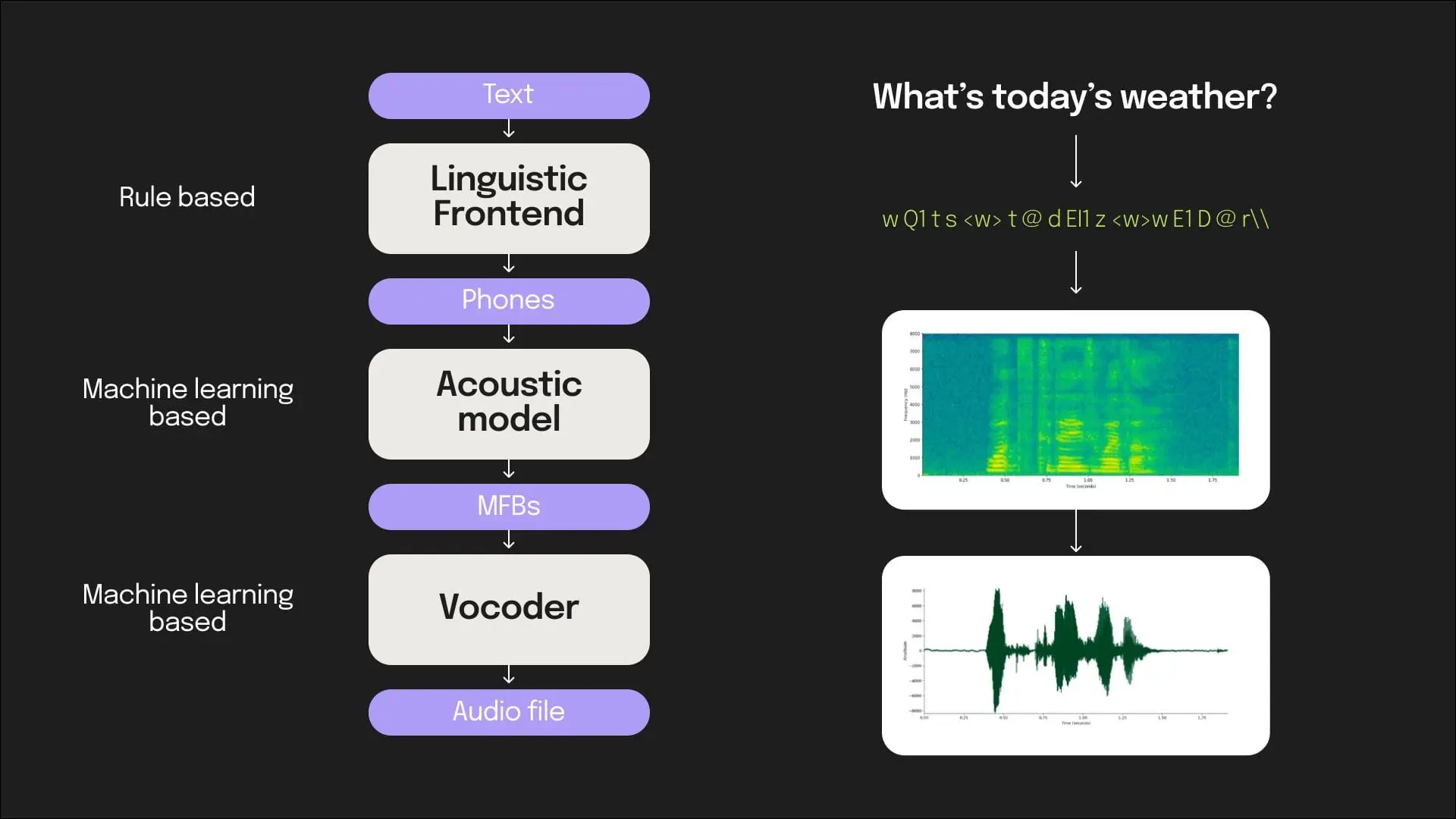
While these system architectures served their purpose, and allowed us to produce natural sounding speech, they struggle to produce an extended expressive range (like laughter and disfluencies) , or the generated speech ends up sounding robotic. Some examples of such speech:
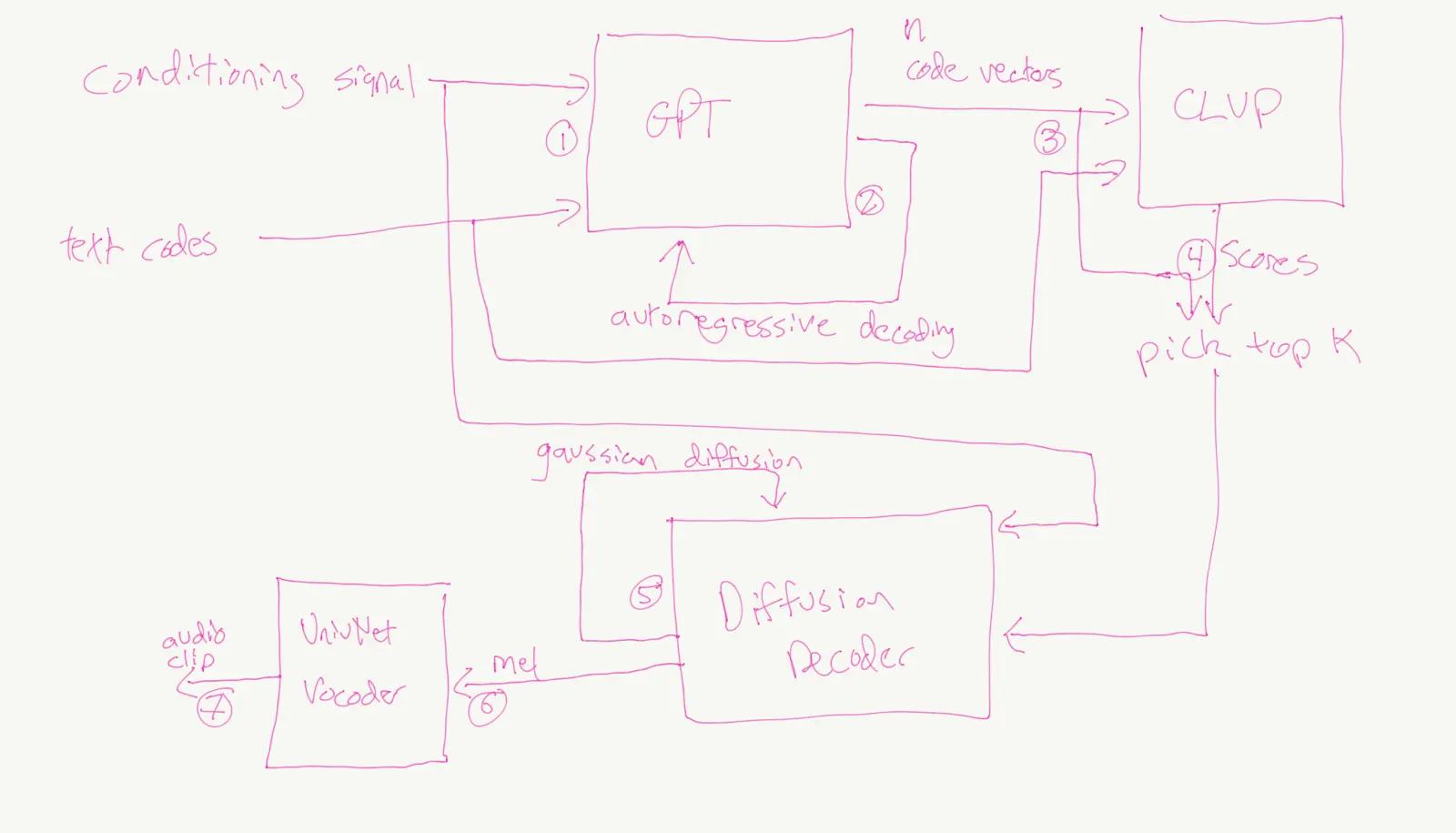
Tortoise TTS, architectural notes from the author (presumably with an iPad in bed)
In the last couple of years, there has been a large speech modelling boom. Tortoise TTS—implemented by a person sitting in his bedroom with GPUs sponsored by NVIDIA—is considered seminal in this domain. It showed us that with simple but scalable models and large amounts of clean data, some powerful models could be developed. Major research departments like Microsoft Research also designed and trained powerful models around the same time – such as Vall-E. These next-generation TTS models unlocked a new range of emotion and expressivity in speech.
Listen to an example from Tortoise V2 below. More can be found here.
The importance of data
These new generations of GPT-powered large models are beautiful (to the trained eye). They scale elegantly, but they’re also extremely data-hungry. The speech community indicates that a typical from-scratch training experiment requires between tens of thousands and approximately 100,000 hours of speech data.
- The VALL-E-2 model was trained on 50k hours of speech data
- Tortoise V2 was trained on 50k hours of speech data.
- Metavoice 1B was trained with 100k hours of speech data.
It’s not just the data size that matters; it’s the quality. We’ve seen instances in which the performance of smaller models trained on the right quality data is as high as that of much bigger models. On the flip side, we’ve also seen that pre-trained models can be fine-tuned (An OpenAI FAQ section on finetuning) with a few iterations and small amounts of high-quality data.
This brings up interesting challenges in speech. “Unclean” data is often the most interesting. The following examples would be regarded as “unclean” when, in actual fact, they give our models a truer picture of the “messiness” of human communication. To produce realistic synthetic speech, we need our models to learn the full breadth of human communication, including:
- People talking over each other
- People singing along while there music in the background
- People introducing disfluencies, like laughter, and/or noises as they are speaking
- People code-switching several times in the same sentence
These scenarios are extremely valuable for a model to capture and perhaps even output. How cool would it be for a model to switch between 3 languages, like, when I talk to my parents?
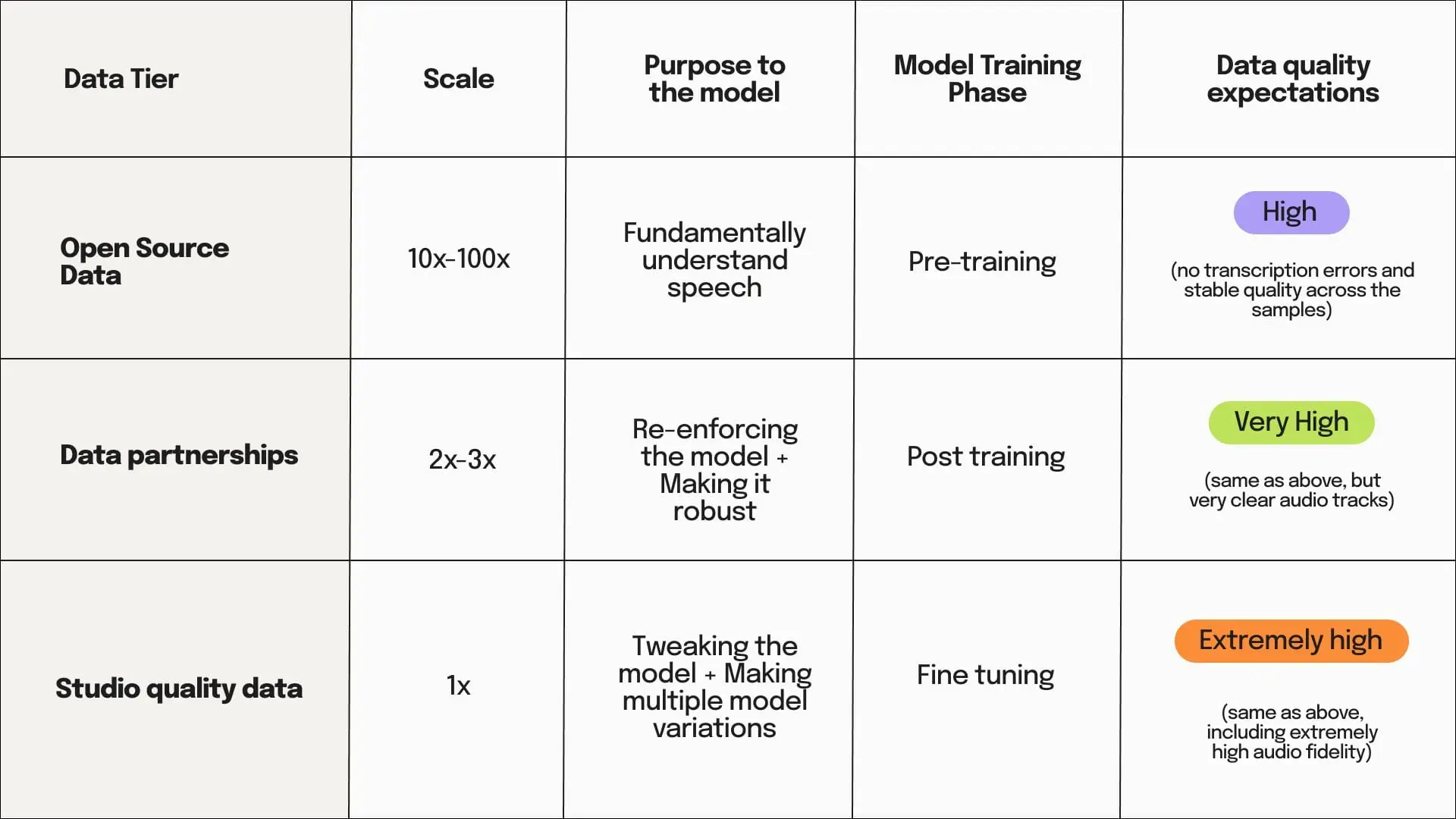
The 3 tiers of data
To produce the best results, we work with large amounts of high-quality data. In the speech world, high-quality data is highly curated studio recordings made by voice actors. However, this high-quality data tier does have downsides.
In order to tackle both these problems, we look to the other two tiers of data:
- Data partnerships: These enable us to trade data for dubbing credits from media owners. This data is not as high quality as studio data (although it might be in some cases), but it has a wide range.
- Open source data: The world is filled with audio data. It has varying levels of quality and a large range of expressivity. Several speech datasets have emerged in the last couple of years such as MultiLingual LibreSpeech (~50k hours) and Yodas v2(~500k hours). Tagging and processing such a large scale of data that spans across a massive expressivity range would be hugely beneficial for a model to fundamentally understand speech.
All these tiers of data have their place in training a single model.
The large data problem
Therefore, before embarking on a large model training plan, we plan how much data we need in each of the above buckets.
Large data comes with large data problems. Fundamentally, there are several nuances when dealing with large amounts of data across many datasets that represent a large quality range. As a rule of thumb, you can assume that a very small percentage of the data one might process can actually be used for model training (high-quality data), i.e the yield is low. This yield can be anywhere from 10% to 90% depending on the data source.
The automation problem
Processing large amounts of data is inefficient if downstream steps require human intervention. We don’t want a system where a human manually triggers various processing steps, and needs to know about how the data was processed in order to use. Therefore, it is essential to fully automate one’s data pipeline to get the most out of the system. The data pipeline needs to do things like:
- Importing the data: Either copying the data to an internal data store, or linking to it, at speed.
- Labelling/Tagging the data: In some cases, the data needs to be labelled. Thankfully, many best-in-class ML models exist for these auxiliary speech tasks.
- Feature extraction: Once the data is labelled and broken down for training purposes, feature extraction helps us extract more information from the data. This is used both to feed the model in training with additional context and to filter down the dataset further for specific purposes.
- Updating the data: Quite often, the data requires updating due to a variation in the processing step. Therefore, the data needs to be versioned.
- Adaptive filtering: Once the data has been recorded into datasets, the downstream task (model training) must determine the required level of data cleanliness (that is, the level of “clean data” required). This can be solved by adaptive filtering mechanisms based on the labels and features extracted in the previous steps, with quality thresholds. Such a filtering mechanism essentially translates into a query such as “Please get me all the audio files where I do not have music in the background, and I have highly energetic speech”
The above steps are like a series of giant filters. These filters serially reject a lot of data, thereby creating the concept of pipeline yield that we mentioned above. At the end of this pipeline, we expect to arrive at high-quality, well-represented, expressive datasets across multiple languages and domains. This is also the secret sauce with which we enrich existing, open-source, publicly available data.
The scale problem
Just as a series of giant filters help us to overcome the problem of automation, we must tackle the following to overcome the challenge of processing large amounts of data.
-
Storage and systems: The system design for a large scale data pipeline needs to be intentional from the outset.
- Know your scale: We needed to store large amounts of data, to the tune of 100s of terabytes. This needs to be optimized for cost, but wisely, has to be optimised for latencies as well, as it is usually machine learning models that consume this data.
- It’s never just one version: In addition, processing the data entails the creation of “processed” versions of that data which are relevant for model training. A point to note here is that the processing methods change over time, as one learns more about their data, which might result in several versions of the processed data. As a result, it becomes important for the system to have a mechanism to store multiple versions of the processed data, which is enabled by introducing the concept of data versioning across the data stack.
- You always want know your source: As a final point, for all the data that the machine learning model consumes, its important to know how it was processed and where it was obtained from – this is enabled by introducing the concept of data lineage.
Here is a nice blog post about some of the concepts mentioned above.
-
Compute: To turn our automated pipeline towards large amounts of data, it’s important for us to be able to do that at scale. Therefore a high throughput data pipeline orchestration system is required, at two levels → a) to orchestrate the functional interaction with large amounts of compute and b) to orchestrate the various stages in the automated pipeline. While doing this, it’s important for us to right size our compute for each functional stage.
-
Cost: All this storage, compute and network costs money. So, here’s how we manage that:
- Keep data close to usage location: In the cloud, egress turns out to be the biggest data nightmare, so we wanted to avoid that in all circumstances
- Right-sizing: As mentioned above, right-sizing solves many cost-related issues related to computing. In addition, it allows us to use many low-powered devices on a large scale.
- Development cycles: One mechanism to keep human cost low is to keep our development cycles simple and iterate fast. This allows us to spend less human time.
Contingencies
Solving the scale problems is one thing, but the next thing is to plan for it.
- Track a metric: To calculate the cost and improve forecasting, we define a metric for the cost of a unit of model-ready data, which captured three things: acquisition cost, processing cost and storage cost. Likewise, we define a metric to capture the time taken to process and arrive at a unit of data. This allows us to forecast and budget for the amount of data required.
- Plan ahead: There are certain things one can plan for ahead of time
- Quotas: If your cloud provider has quotas, get them out of the way as early as possible
- Stakeholders: If you need to align various functional resources from various teams, do it ahead of time.
- Access: Define access controls and mechanisms ahead of time.
- Predefine quality bars: In addition to different data tiers, we apply varying levels of quality filters to slice datasets across three quality bars: Gold, Silver, and Bronze, respectively, which represent extremely high-quality, medium-quality, and lower-quality open source data. Predefining what “good” quality data turns out to be important to monitor the system and identify early bugs in your pipeline. It also helps you promote data to higher quality tiers as you fix data bugs.
- Always have a Plan B: When dealing with anything at scale, we must be fault-tolerant. Not only on the code side of things but also on the project management and human side of things
- Prepare for running out of compute: Depending on how much scale you’re requesting, that level of compute might not always be available with your cloud provider. Always plan for an alternate instance type or mechanism to fulfil your compute request.
- Prepare for the 1% bug: A small run of your pipeline might give you great data. However, this might not expose all the bugs. If there is a bug that affects 1% of your data, this might not be seen in small runs, and the impact of this could be extremely large in large-scale data. For example, we’ve seen OpenAI’s Whisper model dramatically fail at transcribing numerals.
- Prepare to iterate: The proof of the pudding when it comes to data lies in how useful it is for the model. Prepare to iterate on the data processing stages to align with a moving target, which is model training.
As we move into a future where speech models are capable of capturing and reproducing even the most nuanced aspects of human communication, from hesitations to humor, the quality and quantity of the data used to train these models become crucial. At Papercup, we embrace this challenge head-on, harnessing vast, high-quality data and refining our automated pipelines to deliver human-sounding AI dubbing that’s more than just accurate—it’s expressive. Our approach allows us to seamlessly bridge language barriers while preserving the emotional and cultural nuances that make content truly resonate with audiences worldwide.